Crawler
Overview
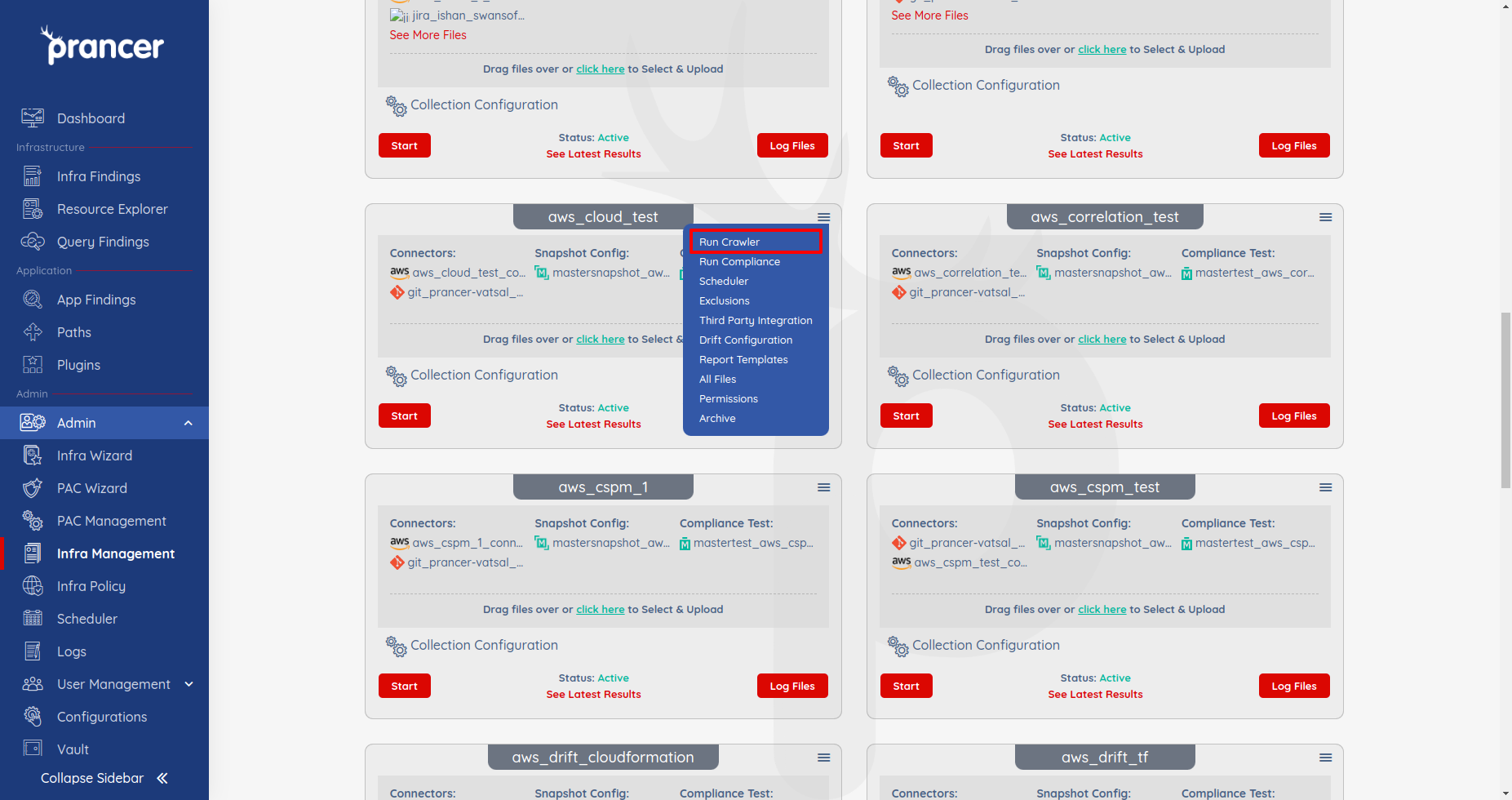
This page discusses the concept of Crawler, which is a process that auto-generates Snapshot files based on MasterSnapshot files. The MasterSnapshot file contains the path to some resource type, and after executing the Crawler, it generates the Snapshot file, which includes all available resources of that resource type. The post provides more information about Crawler and its usage for Google, AWS, and Azure. To run the Crawler, the user needs to select "Run Crawler" from the collection drop-down after ensuring that the selected container has Mastersnapshot and Mastercompliance files. Finally, the user can view the logs in the Log Screen after executing the Crawler.
- Crawler is the process of auto-generating Snapshot files based on MasterSnapshot files.
- The MasterSnapshot file contains the path to some resource type, and after execution of Crawler, it will generate the Snapshot file, which includes all resources available of that resource type.
- You can get more ideas about Crawler from here.
Prancer Allow Following Crawler
- Google Crawler
- AWS Crawler
- Azure Crawler
Run Crawler
- The user can run the Crawler by clicking on the drop-down in collections and choosing
Run Crawler. - Before running the Crawler, the user needs to make sure that the selected container has Mastersnapshot and Mastercompliance.
- After executing the Crawler user can see the logs in Log Screen.